From January-March 2022 I embarked on a 9 week intensive data science coding bootcamp at Le Wagon London. I had a truly fantastic learning experience, but I’m a little anxious about what happens now. Here’s my reflections on how it went and what my next steps are.

Why?
I’ve been a librarian for 10 years and whilst I did really love some aspects of being an information professional (especially helping people, and the community of fantastic colleagues), I kept coming up against the same organisational barriers repeatedly: “we’ve always done it this way”, having to fight very hard to justify “value”, lack of resources. I was also disillusioned by structural issues in the public sector and the academic publishing hellscape, and how little progress has been made in these areas over the past decade. Opportunities in libraries are few and far between, and it seemed to me like these were sector-wide issues that would be hard to escape. I felt frustrated and was looking for a change.
Two of my friends had done the web development bootcamp at Le Wagon London and had so many positive things to say about their experiences. They had successfully changed from careers as professional classical musicians to software development in their 30s, and I thought that their success showed that maybe a change would be possible for me too! So after doing some research into coding bootcamps, I got in touch with Le Wagon, scheduled my admissions interview, and took the plunge. The data science course looked more interesting to me than the web development course, and I thought it would utilise more of my existing professional skill set.
Preparing for the course
Coding bootcamps are not cheap – mine cost £6,900 and as it’s full time, you won’t be able to work and get any income for the duration of the course and probably for a few months after as you job hunt. So I’d say you’d need at least 6 months of living expenses saved up, as well as the course fees. Money is now very tight for me and I’m lucky to have a supportive partner. Some of the people on my course were able to get their workplaces to provide unpaid study leave whilst they studied, and had a job to return to afterwards. There is one scholarship available, which I applied for but was not successful in obtaining. You can also study part-time (16 hours a week), but I think this would only work if you were working part-time as well, not full-time, as it’s really all just a bit much to handle. I’ll discuss the intensity of the learning experience later – it takes a lot out of you but is worth it.
The people on my course were varied. Broadly they fell into two camps – people in their late 20s and up looking for a career change (like me) or recent graduates straight out of uni with little to no professional experience who wanted something to spice up their CVs. We had a 50/50 gender split on the course and at least 8 people of colour out of a class of 32.
Some basic knowledge of Python, algebra, calculus, and statistics was required. We had an admissions test and about 40 hours of prep work to complete before the course started. I had not studied maths formally since GCSEs (all my higher education qualifications are in arts and social sciences subjects), but I have taught medical statistics as part of my professional responsibilities in the past and was always good at maths at school. I did a lot of homework to prepare and still feel some imposter syndrome in this area. I didn’t know any Python before I registered for the course but as my previous blog posts show, I’m pretty happy to teach myself basic coding skills, and there are so many courses available for free.
A typical study day
Classes were from 9am-6pm, Monday-Friday. The day would begin with a lecture from 9-1030, followed by ‘challenges’ for us to work through individually on the online learning platform. The challenges are automatically marked and progress is tracked. Each day, we were randomly allocated one of our coursemates as a ‘buddy’ – someone to turn to for help and to discuss our work with throughout the day. You can see your buddy’s progress through the challenges, and if they are behind you are encouraged to check in on them before moving on. This was a great way to get to know the other people on the course and was instrumental to the building of an exceptional learning community. If we still remained stuck or needed further clarification, we could request 1:1 help from a teaching assistant. I usually requested help between 1-5 times per day and the 1:1 teaching was (with only a couple of exceptions) great. At 5pm, we would reconvene for a recap of the key learning points. In the evening, there were flashcards to complete, which again reiterated the day’s learning objectives. If you hadn’t done these by 8pm, you got an automated message reminding you to do so. The last 2 weeks of the course did not follow this structure as they were fully dedicated to our projects, which I’ll elaborate on later.
When I did the course it was fully hybrid and I thought this worked really well. I caught covid and had to self-isolate for 2 weeks during the course. It was one of the most tiring things I’ve ever had to do, studying online whilst ill, but I’m so grateful that I was able to complete the course despite this and didn’t have to defer. Some of my coursemates had childcare responsibilities or disabilities and I know that the hybrid format really worked for them too. I did enjoy the on campus experience – it was easier to form social connections and to ask questions – but my commute was over an hour each way, so I appreciated having the flexibility to use that time in other ways, if needed. A fully remote option is also available.
What did I learn?
The number of topics covered over the duration of the 7 weeks of teaching was mind boggling. We raced from topic to topic, building on previous things that we had learned. We’re encouraged to use this template text to summarise our learning on our CVs, which is a real mouthful but does drive home how much was covered:
I studied Data Analytics with SQL, BigQuery, Pandas, Numpy, and Matplotlib; Statistics with Scipy, Seaborn and Statsmodels; Machine Learning with Scikit-learn; Deep Learning with TensorFlow Keras; and developed Data Products with Google Cloud Platform, Docker, Heroku and Streamlit.
We also learned to use Git, Github and the Linux command line. Being switched on from 9am-6pm 5 days a week was incredibly tiring – combined with my commute, I had barely any energy for anything else in my life during the 9 weeks. It was an incredibly intensive experience, but one that I really thrived on.
Where Le Wagon really excelled was in building a cohesive ‘learning community’ – by the end of the whole bootcamp we had really gelled as a team. Of course the standard varied within our class – some people were absolute whizzes, utilising packages and data engineering tools not even covered on our course, whilst a few struggled to keep up with the pace. But we all got along well and helped each other out, and I made some excellent friendships.
The way in which the teaching was scaffolded was really interesting to me from a pedagogical point of view. We had a few days of ‘mini projects’ which gave us the opportunity to practice actual coding concepts, whilst also exercising softer skills such as project management, teamwork, and communication. The combination of live lectures, pre-recorded versions of the same lecture we could go back to, guided exercises, 1:1 support, daily recaps and flashcards all worked well to help us understand and retain all the information we were given.
The projects that we worked on were really varied and interesting. All the project ideas were generated by our peers, we had a ‘pitch night’ which was a bit gameshow-esque where we presented our ideas and had to vote on the projects we wanted to work on! The project was a fantastic way to utilise our skills in a ‘real world’ scenario. I worked on creating a deep learning abstract art generator, and utilised transfer learning and machine learning to find similar images to what our generator had created in the dataset. You can see a video of our presentation above and view our live website here https://share.streamlit.io/FlavKV/website/website.py. It was such a change working in a relatively unstructured/unsupervised way and it really brought everything together. I loved checking in with the other groups every day and seeing all the other amazing things they built, such as a model for detecting respiratory diseases from audio tracks of lung auscultations https://youtu.be/W1zSTjx_0MI , and a comedy bot trained on standup routines https://youtu.be/PqE2JQ-mf8I.
We’re going on a job hunt
So what happens next? There was a career week at Le Wagon the week after we finished, which was really helpful. We spruced up our CVs, Github, and Linkedin profiles, and wrote some cover letters. I’ve been applying for about 5-10 jobs per week and it’s been a little disheartening so far with little to no response, but I will keep persevering. I don’t have a quantitative background, which is on a lot of job descriptions. My motto when job hunting is to think “what would a mediocre white man do?” – I’m trying to embody a confidence and self assurance that is not really there! I finally felt after 10 years as a librarian that I kind of knew what I was doing, but now I’m a fish out of water.
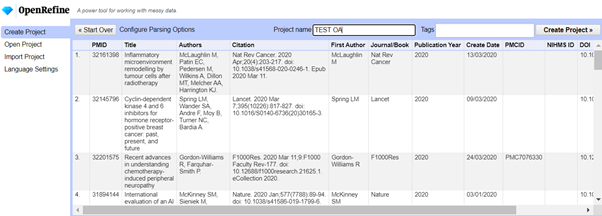
My priority for the moment is to jazz up my portfolio – I’m working on a few projects, including an analysis of NHS research publications https://github.com/yiwen-h/nhs_oa. I also have a part-time job as a teaching assistant at Le Wagon helping the next batch of wannabe data scientists which has been great for revising the course materials.
This next step is both challenging and terrifying and I’ve been feeling very anxious about it. But nothing ventured, nothing gained – let’s see what happens next. If you want some data analysed or cleaned, get in touch! I’m available as a freelancer now 😉